Underdetermined Linear Systems
Contents
18.3. Underdetermined Linear Systems#
The discussion in this section is primarily based on chapter 1 of [30].
Consider a matrix \(\Phi \in \CC^{M \times N}\) with \(M < N\).
Define an under-determined system of linear equations:
\[ \Phi \bx = \by \]where \(\by \in \CC^M\) is known and \(\bx \in \CC^N\) is unknown.
This system has \(N\) unknowns and \(M\) linear equations.
There are more unknowns than equations.
Let the columns of \(\Phi\) be given by \(\phi_1, \phi_2, \dots, \phi_N\).
Column space of \(\Phi\) (vector space spanned by all columns of \(\Phi\)) is denoted by \(\ColSpace(\Phi)\); i.e.,
\[ \ColSpace(\Phi) = \sum_{i=1}^{N} c_i \phi_i, \quad c_i \in \CC. \]We know that \(\ColSpace(\Phi) \subset \CC^M\).
Clearly \(\Phi \bx \in \ColSpace(\Phi)\) for every \(\bx \in \CC^N\).
Thus if \(\by \notin \ColSpace(\Phi)\) then we have no solution.
But, if \(\by \in \ColSpace(\Phi)\) then we have infinite number of solutions.
Let \(\NullSpace(\Phi)\) represent the null space of \(\Phi\) given by
\[ \NullSpace(\Phi) = \{ \bx \in \CC^N : \Phi \bx = \bzero \}. \]Let \(\widehat{\bx}\) be a solution of \(\by = \Phi \bx\).
Let \(\bz \in \NullSpace(\Phi)\).
Then
\[ \Phi (\widehat{\bx} + \bz) = \Phi \widehat{\bx} + \Phi \bz = \by + \bzero = \by. \]Hence \(\widehat{\bx} + \bz\) is also a solution of of the system \(\Phi \bx = \by\).
Thus the set \(\widehat{x} + \NullSpace(\Phi)\) forms the complete set of infinite solutions to the problem \(\by = \Phi \bx\) where
\[ \widehat{\bx} + \NullSpace(\Phi) = \{\widehat{\bx} + \bz \ST \bz \in \NullSpace(\Phi)\}. \]
Example 18.2 (An under-determined system)
As a running example in this section, we will consider a simple under-determined system in \(\RR^2\).
The system is specified by
and
with
where \(\bx\) is unknown and \(y\) is known. Alternatively
or more simply
The solution space of this system is a line in \(\RR^2\).
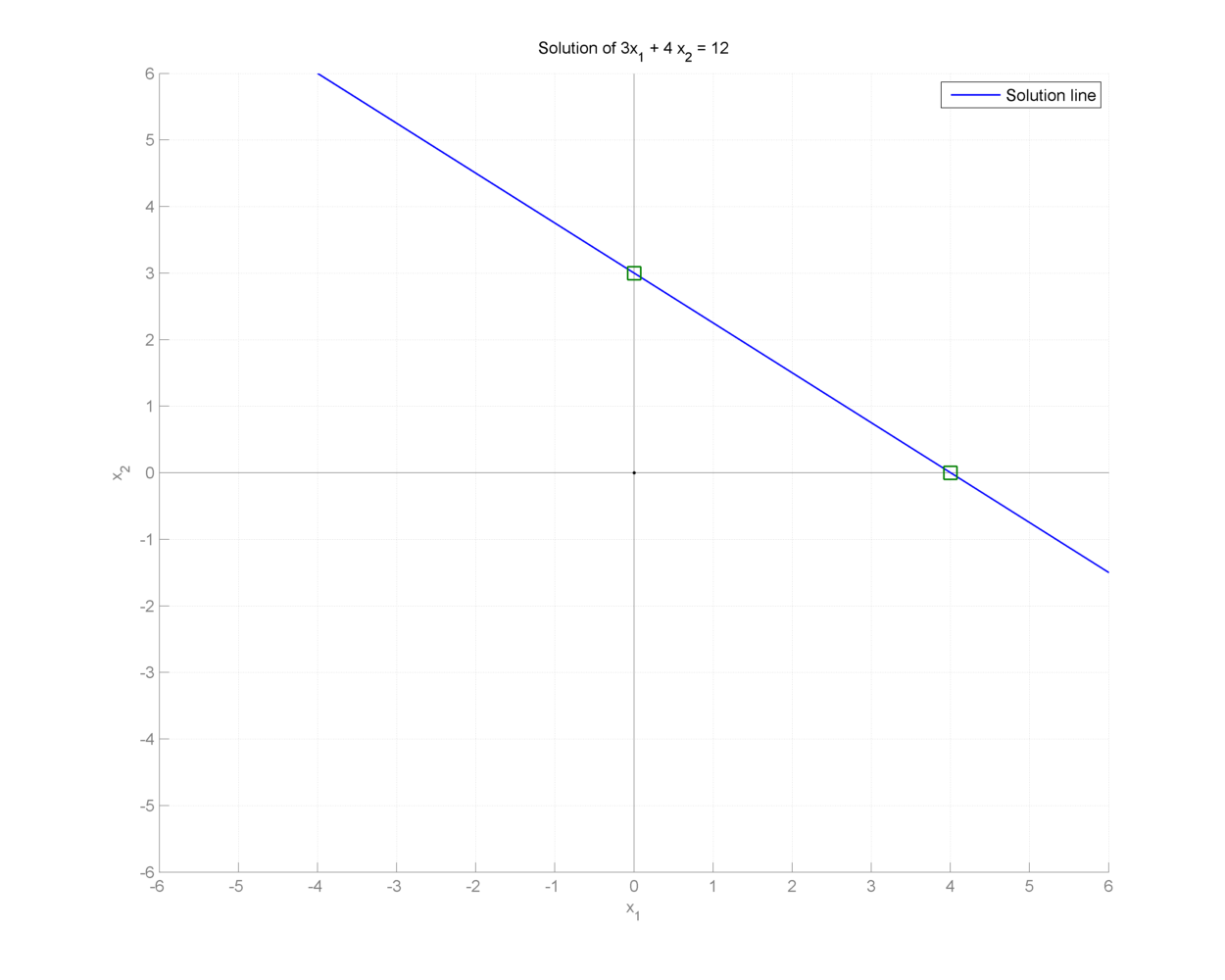
Fig. 18.1 An underdetermined system#
Specification of the under-determined system as above, doesn’t give us any reason to pick one particular point on the line as the preferred solution.
Two specific solutions are of interest
\((x_1, x_2) = (4,0)\) lies on the \(x_1\) axis.
\((x_1, x_2) = (0,3)\) lies on the \(x_2\) axis.
In both of these solutions, one component is 0, thus leading these solutions to be sparse.
It is easy to visualize sparsity in this simplified 2-dimensional setup but situation becomes more difficult when we are looking at high dimensional signal spaces. We need well defined criteria to promote sparse solutions.
18.3.1. Regularization#
Are all these solutions equivalent or can we say that one solution is better than the other in some sense? In order to suggest that some solution is better than other solutions, we need to define a criteria for comparing two solutions.
In optimization theory, this idea is known as regularization.
We define a cost function \(J(x) : \CC^N \to \RR\) which defines the desirability of a given solution \(x\) out of infinitely possible solutions. The higher the cost, lower is the desirability of the solution.
Thus the goal of the optimization problem is to find a desired \(\bx\) with minimum possible cost.
We can write this optimization problem as
If \(J(\bx)\) is convex, then its possible to find a global minimum cost solution over the solution set.
If \(J(\bx)\) is not convex, then it may not be possible to find a global minimum, we may have to settle with a local minimum.
A variety of such cost function based criteria can be considered.
18.3.2. \(\ell_2\) Regularization#
One of the most common criteria is to choose a solution with the smallest \(\ell_2\) norm.
The problem can then be reformulated as an optimization problem
We can see that minimizing \(\| \bx \|_2\) is same as minimizing its square \(\| \bx \|_2^2 = \bx^H \bx\); i.e., both functions have exactly the same minimizer under the given constraints.
Hence an equivalent formulation is
Example 18.3 (Minimum \(\ell_2\) norm solution for an under-determined system)
We continue with our running example.
We can write \(\bx_2\) as
With this definition the squared \(\ell_2\) norm of \(x\) becomes
Minimizing \(\| \bx \|_2^2\) over all \(\bx\) is same as minimizing over all \(x_1\).
Since \(\| \bx \|_2^2\) is a quadratic function of \(x_1\), we can simply differentiate it and equate to 0 giving us
This gives us
Thus the optimal \(\ell_2\) norm solution is obtained at \((x_1, x_2) = (1.44, 1.92)\).
We note that the minimum \(\ell_2\) norm at this solution is
It is instructive to note that the \(\ell_2\) norm cost function prefers a non-sparse solution to the optimization problem.
We can view this solution graphically by drawing \(\ell_2\) norm balls of different radii. The ball which just touches the solution space line (i.e. the line is tangent to the ball) gives us the optimal solution.
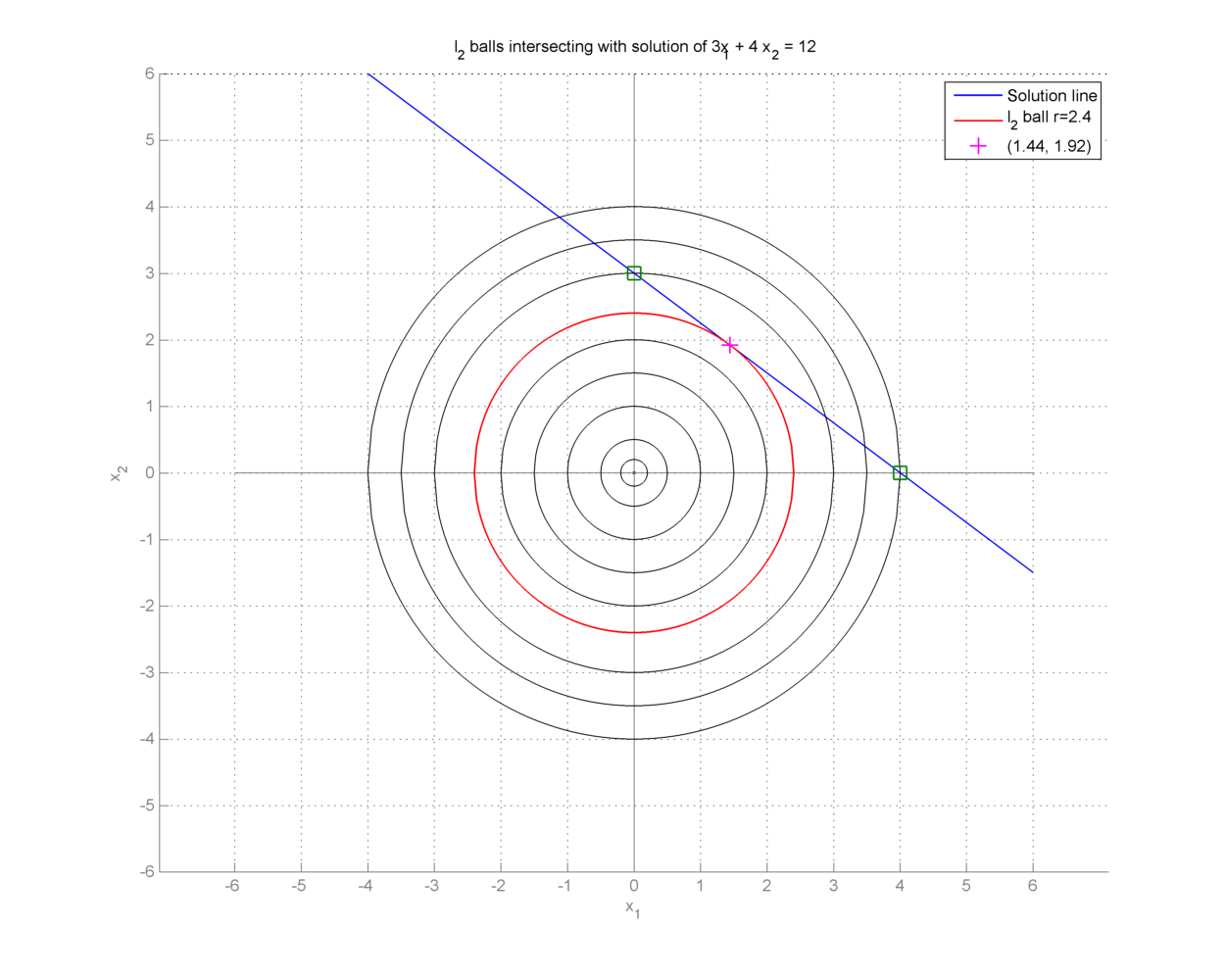
Fig. 18.2 Minimum \(\ell_2\) norm solution for the under-determined system \(3 x_1 + 4 x_2 = 12\)}#
All other norm balls either don’t touch the solution line at all, or they cross it at exactly two points.
Remark 18.1 (Least squares via Lagrangian multipliers)
A formal solution to \(\ell_2\) norm minimization problem can be easily obtained using Lagrange multipliers.
We define the Lagrangian
with \(\lambda \in \CC^M\) being the Lagrange multipliers for the (equality) constraint set.
Differentiating \(\LLL(\bx)\) w.r.t. \(\bx\) we get
By equating the derivative to \(\bzero\) we obtain the optimal value of \(\bx\) as
Plugging this solution back into the constraint \(\Phi \bx = \by\) gives us
In above we are implicitly assuming that \(\Phi\) is a full rank matrix. Hence \(\Phi \Phi^H\) is invertible and positive definite.
Putting \(\lambda\) back in the expression for \(\bx^*\) we obtain the well known closed form least squares solution using pseudo-inverse solution
We would like to mention that there are several iterative approaches to solve the \(\ell_2\) norm minimization problem (like gradient descent and conjugate descent). For large systems, they are more effective than computing the pseudo-inverse.
The beauty of \(\ell_2\) norm minimization lies in its simplicity and availability of closed form analytical solutions. This has led to its prevalence in various fields of science and engineering. But \(\ell_2\) norm is by no means the only suitable cost function. Rather the simplicity of \(\ell_2\) norm often drives engineers away from trying other possible cost functions. In the following, we will look at various other possible cost functions.
18.3.2.1. Convexity#
Convex optimization problems have a unique feature that it is possible to find the global optimal solution if such a solution exists.
The solution space \( \Omega = \{\bx : \Phi \bx = \by\}\) is convex. Thus the feasible set of solutions for the optimization problem (18.1) is also convex. All it remains is to make sure that we choose a cost function \(J(x)\) which happens to be convex. This will ensure that a global minimum can be found through convex optimization techniques. Moreover, if \(J(x)\) is strictly convex, then it is guaranteed that the global minimum solution is unique. Thus even though, we may not have a nice looking closed form expression for the solution of a strictly convex cost function minimization problem, the guarantee of the existence and uniqueness of solution as well as well developed algorithms for solving the problem make it very appealing to choose cost functions which are convex.
We recall that all \(\ell_p\) norms with \(p \geq 1\) are convex functions. In particular \(\ell_{\infty}\) and \(\ell_1\) norms are very interesting and popular where
and
In the following section we will attempt to find a unique solution to our optimization problem (18.1) using \(\ell_1\) norm.
18.3.3. \(\ell_1\) Regularization#
In this subsection we will restrict our attention to the Euclidean space case where \(\bx \in \RR^N\), \(\Phi \in \RR^{M \times N}\) and \(\by \in \RR^M\).
We choose our cost function \(J(\bx) = \| \bx \|_1\). The cost minimization problem can be reformulated as
Example 18.4 (Minimum \(\ell_1\) norm solution for an under-determined system)
We continue with our running example. we can view this solution graphically by drawing \(\ell_1\) norm balls of different radii. The ball which just touches the solution space line gives us the optimal solution.
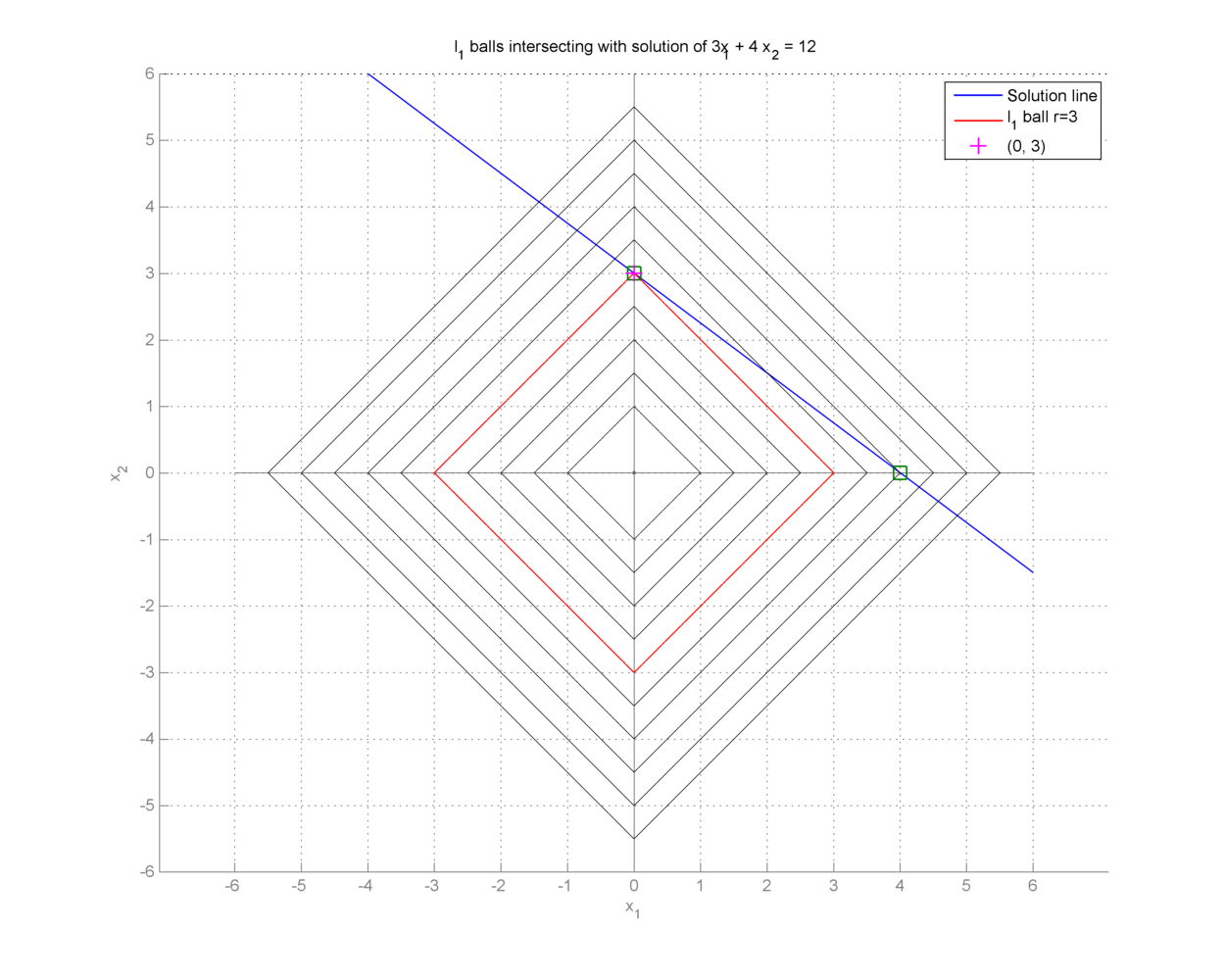
Fig. 18.3 Minimum \(\ell_1\) norm solution for the under-determined system \(3 x_1 + 4 x_2 = 12\)#
As we can see from the figure the minimum \(\ell_1\) norm solution is given by \((x_1,x_2) = (0,3)\).
It is interesting to note that \(\ell_1\) norm solution promotes sparser solutions while \(\ell_2\) norm solution promotes solutions in which signal energy is distributed among all of its components.
It is time to have a closer look at our cost function \(J(x) = \| \bx \|_1\). This function is convex yet not strictly convex.
Example 18.5 (\(| x|_1\) is not strictly convex)
Consider again \(\bx \in \RR^2\). For \(\bx \in \RR_+^2\) (the first quadrant),
Hence for any \(c_1, c_2 \geq 0\) and \(\bx, \by \in \RR_+^2\):
Thus, \(\ell_1\)-norm is not strictly convex. Consequently, a unique solution may not exist for \(\ell_1\) norm minimization problem.
As an example consider the under-determined system
We can easily visualize that the solution line will pass through points \((0,4)\) and \((4,0)\).
Moreover, it will be clearly parallel with \(\ell_1\)-norm ball of radius \(4\) in the first quadrant.
This gives us infinitely possible solutions to the minimization problem (18.3).
We can still observe that
these solutions are gathered in a small line segment that is bounded (a bounded convex set) and
There exist two solutions \((4,0)\) and \((0,4)\) among these solutions which have only 1 non-zero component.
For the \(\ell_1\) norm minimization problem since \(J(\bx)\) is not strictly convex, hence a unique solution may not be guaranteed. In specific cases, there may be infinitely many solutions. Yet what we can claim is
these solutions are gathered in a set that is bounded and convex, and
among these solutions, there exists at least one solution with at most \(M\) non-zeros (as the number of constraints in \(\Phi \bx = \by\)).
Theorem 18.1 (Existence of a sparse solution for \(\ell_1\) minimization)
Let \(S\) denote the solution set of \(\ell_1\) norm minimization problem (18.3). \(S\) contains at least one solution \(\widehat{x}\) with \(\| \widehat{x} \|_0 = M\).
Proof. We have the following facts
\(S\) is convex and bounded.
\(\Phi \bx^* = \by \, \Forall \bx^* \in S\).
Since \(\Phi \in \RR^{M \times N}\) is full rank and \(M < N\), hence \(\rank \Phi = M\).
We proceed as follows.
Let \(\bx^* \in S\) be an optimal solution with \(\| \bx^* \|_0 = L > M\).
Consider the \(L\) columns of \(\Phi\) which correspond to \(\supp(\bx^*)\).
Since \(L > M\) and \(\rank \Phi = M\) hence these columns linearly dependent.
Thus there exists a nonzero vector \(\bh \in \RR^N\) with \(\supp(\bh) \subseteq \supp(\bx^*)\) such that
\[ \Phi \bh = \bzero. \]Note that since we are only considering those columns of \(\Phi\) which correspond to \(\supp(\bx)\), hence we require \(h_i = 0\) whenever \(\bx^*_i = 0\).
Consider a new vector
\[ \bx = \bx^* + \epsilon \bh \]where \(\epsilon\) is small enough such that every element in \(\bx\) has the same sign as \(\bx^*\). As long as
\[ |\epsilon| \leq \underset{i \in \supp(\bh)}{\min} \frac{|\bx^*_i|}{|h_i|} = \epsilon_0 \]such an \(\bx\) can be constructed.
Note that \(x_i = 0\) whenever \(x^*_i = 0\).
Clearly
\[ \Phi \bx = \Phi (\bx^* + \epsilon \bh) = \by + \epsilon \bzero = \by. \]Thus \(\bx\) is a feasible solution to the problem (18.3) though it need not be an optimal solution.
But since \(\bx^*\) is optimal hence, we must assume that \(\ell_1\) norm of \(\bx\) is greater than or equal to the \(\ell_1\) norm of \(\bx^*\)
\[ \| \bx \|_1 = \|\bx^* + \epsilon \bh \|_1 \geq \| \bx^* \|_1 \Forall |\epsilon| \leq \epsilon_0. \]Now look at \(\|\bx \|_1\) as a function of \(\epsilon\) in the region \(|\epsilon| \leq \epsilon_0\).
In this region, \(\ell_1\) function is continuous and differentiable (w.r.t. \(\epsilon\)) since all vectors \(\bx^* + \epsilon \bh\) have the same sign pattern.
If we define \(\by^* = | \bx^* |\) (the vector of absolute values), then
\[ \| \bx^* \|_1 = \| \by^* \|_1 = \sum_{i=1}^N y^*_i. \]Since the sign patterns don’t change, hence
\[ |x_i| = |x^*_i + \epsilon h_i | = y^*_i + \epsilon h_i \sgn(x^*_i). \]Thus
\[\begin{split} \|\bx \|_1 &= \sum_{i=1}^N |x_i| \\ &= \sum_{i=1}^N \left (y^*_i + \epsilon h_i \sgn(x^*_i) \right) \\ &= \| \bx^* \|_1 + \epsilon \sum_{i=1}^N h_i \sgn(x^*_i)\\ &= \| \bx^* \|_1 + \epsilon \bh^T \sgn(\bx^*). \end{split}\]The quantity \(\bh^T \sgn(\bx^*)\) is a constant.
The inequality \(\|\bx \|_1 \geq \| \bx^* \|_1\) applies to both positive and negative values of \(\epsilon\) in the region \(|\epsilon | \leq \epsilon_0\).
This is possible only when inequality is in fact an equality.
This implies that the addition / subtraction of \(\epsilon \bh\) under these conditions does not change the \(\ell_1\) length of the solution.
Thus, \(\bx \in S\) is also an optimal solution.
This can happen only if
\[ \bh^T \sgn(\bx^*) = 0. \]We now wish to tune \(\epsilon\) such that one entry in \(x^*\) gets zeroed while keeping the solutions \(\ell_1\) length.
We choose \(i\) corresponding to \(\epsilon_0\) (defined above) and pick
\[ \epsilon = \frac{-x^*_i}{h_i}. \]Clearly for the corresponding
\[ \bx = \bx^* + \epsilon \bh \]the \(i\)-th entry is zeroed while others keep their sign and the \(\ell_1\) norm is also preserved.
Thus, we have got a new optimal solution with \(L-1\) non-zeros at the most.
It is possible that more than 1 entries get zeroed during this operation.
We can repeat this procedure till we are left with \(M\) non-zero elements.
Beyond this we may not proceed since \(\rank \Phi = M\). Hence we cannot say that corresponding columns of \(\Phi\) are linearly dependent.
We thus note that \(\ell_1\) norm has a tendency to prefer sparse solutions. This is a well known and fundamental property of linear programming.
18.3.4. \(\ell_1\) Norm Minimization as a Linear Programming Problem#
We now show that (18.3) in \(\RR^N\) is in fact a linear programming problem.
Recalling the problem:
Let us write \(\bx\) as \(\bu - \bv\) where \(\bu, \bv \in \RR^N\) are both non-negative vectors such that \(\bu\) takes all positive entries in \(\bx\) while \(\bv\) takes all the negative entries in \(\bx\).
Example 18.6 (\(\bx = \bu - \bv\))
Let
Then
And
Clearly \(\bx = \bu - \bv\).
We note here that by definition
i.e., support of \(\bu\) and \(\bv\) are disjoint.
We now construct a vector
We can now verify that
Also
where \(\bz \succeq \bzero\).
Hence the optimization problem (18.3) can be recast as
This optimization problem has the classic Linear Programming structure since the objective function is affine as well as constraints are affine.
Remark 18.2 (Justification for the equivalence of the linear program)
Let \(\bz^* =\begin{bmatrix} \bu^* \\ \bv^* \end{bmatrix}\) be an optimal solution of the linear program (18.4).
In order to show that the two optimization problems are equivalent, we need to verify that our assumption about the decomposition of \(\bx\) into positive entries in \(\bu\) and negative entries in \(\bv\) is indeed satisfied by the optimal solution \(\bu^*\) and \(\bv^*\). i.e., the support of \(\bu^*\) and \(\bv^*\) do not overlap.
Since \(\bz \succeq \bzero\), hence \(\langle \bu^* , \bv^* \rangle \geq \bzero\).
If support of \(\bu^*\) and \(\bv^*\) don’t overlap, then we have \(\langle \bu^* , \bv^* \rangle = \bzero\).
And if they overlap then \(\langle \bu^* , \bv^* \rangle > 0\).
Now for the sake of contradiction, let us assume that support of \(\bu^*\) and \(\bv^*\) do overlap for the optimal solution \(\bz^*\).
Let \(k\) be one of the indices at which both \(u_k \neq 0\) and \(v_k \neq 0\).
Since \(\bz \succeq \bzero\), hence \(u_k > 0\) and \(v_k > 0\).
Without loss of generality let us assume that \(u_k > v_k > 0\).
In the equality constraint
\[\begin{split} \begin{bmatrix} \Phi & -\Phi \end{bmatrix} \begin{bmatrix} \bu \\ \bv \end{bmatrix} = \by \end{split}\]both of these coefficients multiply the same column of \(\Phi\) with opposite signs giving us a term
\[ \phi_k (u_k - v_k). \]Now if we replace the two entries in \(\bz^*\) by
\[ u_k' = u_k - v_k \]and
\[ v_k' = 0 \]to obtain an new vector \(\bz'\), we see that there is no impact in the equality constraint since
\[ \begin{bmatrix} \Phi & -\Phi \end{bmatrix} \bz' = \by. \]Also the nonnegativity constraint
\[ \bz \succeq \bzero \]is satisfied for \(\bz'\).
This means that \(\bz'\) is a feasible solution.
On the other hand the objective function \(\bone^T \bz\) value reduces by \(2 v_k\) for \(\bz'\).
This contradicts our assumption that \(\bz^*\) is the optimal solution.
Hence for the optimal solution of (18.4) we must have
\[ \supp(\bu^*) \cap \supp(\bv^*) = \EmptySet. \]Thus
\[ \bx^* = \bu^* - \bv^* \]is indeed the desired solution for the optimization problem (18.3).