Subspace Clustering
Contents
23. Subspace Clustering#
High dimensional data-sets are now pervasive in various signal processing applications. For example, high resolution surveillance cameras are now commonplace generating millions of images continually. A major factor in the success of current generation signal processing algorithms is the fact that, even though these data-sets are high dimensional, their intrinsic dimension is often much smaller than the dimension of the ambient space.
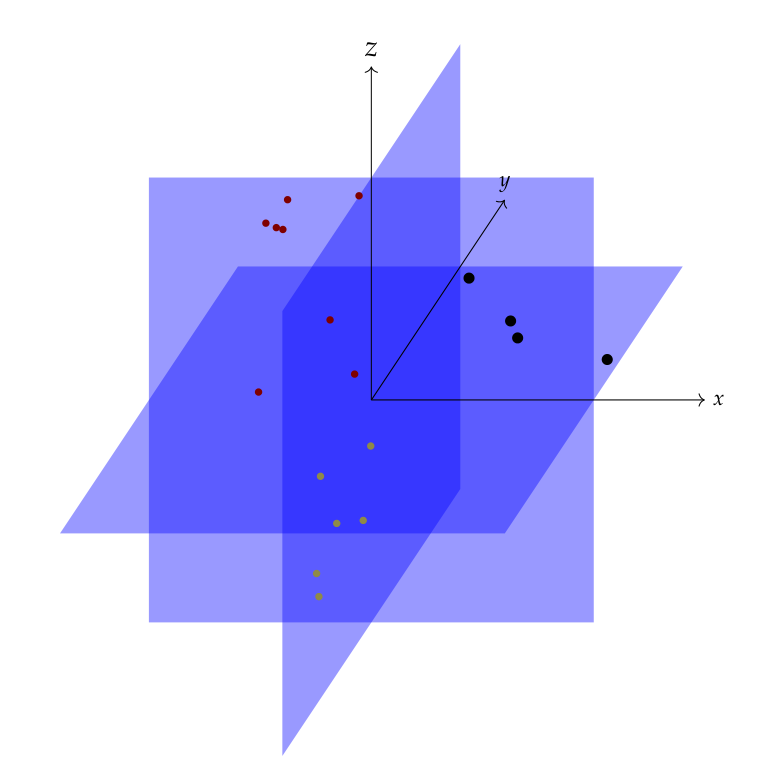
One resorts to inferring (or learning) a quantitative model \(\MM\) of a given set of data points \(\bY = \{ \by_1, \dots, \by_S\} \subset \RR^M\). Such a model enables us to obtain a low dimensional representation of a high dimensional data set. The low dimensional representations enable efficient implementation of acquisition, compression, storage, and various statistical inferencing tasks without losing significant precision. There is no such thing as a perfect model. Rather, we seek a model \(\MM^*\) that is best among a restricted class of models \(\MMM = \{ \MM \}\) which is rich enough to describe the data set to a desired accuracy yet restricted enough so that selecting the best model is tractable.
In absence of training data, the problem of modeling falls into the category of unsupervised learning. There are two common viewpoints of data modeling. A statistical viewpoint assumes that data points are random samples from a probabilistic distribution. Statistical models try to learn the distribution from the dataset. In contrast, a geometrical viewpoint assumes that data points belong to a geometrical object (a smooth manifold or a topological space). A geometrical model attempts to learn the shape of the object to which the data points belong. Examples of statistical modeling include maximum likelihood, maximum a posteriori estimates, Bayesian models etc. An example of geometrical models is Principal Component Analysis (PCA) which assumes that data is drawn from a low dimensional subspace of the high dimensional ambient space. PCA is simple to implement and has found tremendous success in different fields e.g., pattern recognition, data compression, image processing, computer vision, etc. 1.
The assumption that all the data points in a data set could be drawn from a single model however happens to be a stretched one. In practice, it often occurs that if we group or segment the data set \(\bY\) into multiple disjoint subsets: \(\bY = \bY_1 \cup \dots \cup \bY_K\), then each subset can be modeled sufficiently well by a model \(\MM_k^*\) (\(1 \leq k \leq K\)) chosen from a simple model class. Each model \(\MM_k^*\) is called a primitive or component model. In this sense, the data set \(\bY\) is called a mixed dataset and the collection of primitive models is called a hybrid model for the dataset. Let us look at some examples of mixed data sets.
Consider the problem of vanishing point detection in computer vision. Under perspective projection, a group of parallel lines pass through a common point in the image plane which is known as the vanishing point for the group. For a typical scene consisting of multiple sets of parallel lines, the problem of detecting all vanishing points in the image plane from the set of edge segments (identified in the image) can be transformed into clustering points (in edge segments) into multiple 2D subspaces in \(\RR^3\) (world coordinates of the scene).
In the Motion segmentation problem, an image
sequence consisting of multiple moving objects is
segmented so that each segment consists of motion
from only one object. This is a fundamental problem
in applications such as motion capture, vision based navigation,
target tracking and surveillance. We first track the
trajectories of feature points (from all objects) over the image
sequence. It has been shown (see sec:motion_segmentation)
that trajectories of feature points for rigid motion
for a single object form a low dimensional subspace.
Thus motion segmentation problem can be solved by
segmenting the feature point trajectories
for different objects separately and estimating
the motion of each object from corresponding trajectories.
In a face clustering problem, we have a collection of unlabeled images of different faces taken under varying illumination conditions. Our goal is to cluster, images of the same face in one group each. For a Lambertian object, it has been shown that the set of images taken under different lighting conditions forms a cone in the image space. This cone can be well approximated by a low-dimensional subspace [5, 49]. The images of the face of each person form one low dimensional subspace and the face clustering problem reduces to clustering the collection of images to multiple subspaces.

Fig. 23.1 A sample of faces from the Extended Yale Faces dataset B [40]. It contains 16128 images of 28 human subjects under 9 poses and 64 illumination conditions.#
As the examples above suggest, a typical hybrid model for a mixed data set consists of multiple primitive models where each primitive is a (low dimensional) subspace. The data set is modeled as being sampled from a collection or arrangement \(\UUU\) of linear (or affine) subspaces \(\UUU_k \subset \RR^M\) : \(\UUU = \{ \UUU_1 , \dots , \UUU_K \}\). The union of the subspaces2 is denoted as \(Z_{\UUU} = \UUU_1 \cup \dots \cup \UUU_K\). This is indeed a geometric model. In such modeling problems, individual subspaces (dimension and orientation of each subspace and total number of subspaces) and the membership of a data point (a single image in the face clustering problem) to a particular subspace is unknown beforehand. This entails the need for algorithms which can simultaneously identify the subspaces involved and cluster/segment the data points from individual subspaces into separate groups. This problem is known as subspace clustering which is the focus of this paper. An earlier detailed introduction to subspace clustering can be found in [83].
An example of a statistical hybrid model is a Gaussian Mixture Model (GMM) where one assumes that the sample points are drawn independently from a mixture of Gaussian distributions. A way of estimating such a mixture model is the expectation maximization (EM) method.
The fundamental difficulty in the estimation of hybrid models is the “chicken-and-egg” relationship between data segmentation and model estimation. If the data segmentation was known, one could easily fit a primitive model to each subset. Alternatively, if the constituent primitive models were known, one could easily segment the data by choosing the best model for each data point. An iterative approach starts with an initial (hopefully good) guess of primitive models or data segments. It then alternates between estimating the models for each segment and segmenting the data based on current primitive models till the solution converges. On the contrary, a global algorithm can perform the segmentation and primitive modeling simultaneously. In the sequel, we will look at a variety of algorithms for solving the subspace clustering problem.
23.1. Notation#
First some general notation for vectors and matrices.
For a vector \(\bv \in \RR^n\), its support is denoted by \(\supp(\bv)\) and is defined as \(\supp(\bv) \triangleq \{i : v_i \neq 0, 1 \leq i \leq n \}\).
\(|\bv|\) denotes a vector obtained by taking the absolute values of entries in \(\bv\).
\(\bone_n \in \RR^n\) denotes a vector whose every entry is \(1\).
\(\| \bv \|_p\) denotes the \(\ell_p\) norm of \(v\).
\(\| \bv \|_0\) denotes the \(\ell_0\)-“norm” of \(\bv\).
Let \(\bA\) be any \(m \times n\) real matrix (\(\bA \in \RR^{m \times n}\)).
\(a_{i, j}\) is the element at the \(i\)-th row and \(j\)-th column of \(\bA\).
\(\ba_j\) with \(1 \leq j \leq n\) denotes the \(j\)-th column vector of \(\bA\).
\(\underline{a}_i\) with \(1 \leq i \leq m\) denotes the \(i\)-th row vector of \(\bA\).
\(a_{j,k}\) is the \(k\)-th entry in \(\ba_j\).
\(\underline{a}_{i,k}\) is the \(k\)-th entry in \(\underline{a}_i\).
\(\bA_{\Lambda}\) denotes a submatrix of \(\bA\) consisting of columns indexed by \(\Lambda \subset \{1, \dots, n \}\).
\(\underline{\bA}_{\Lambda}\) denotes a submatrix of \(\bA\) consisting of rows indexed by \(\Lambda \subset \{1, \dots, m \}\).
\(|\bA|\) denotes the matrix consisting of absolute values of entries in \(\bA\).
\(\supp(\bA)\) denotes the index set of non-zero rows of \(\bA\).
Clearly, \(\supp(\bA) \subseteq \{1, \dots, m\}\).
\(\| \bA \|_{0}\) denotes the number of non-zero rows of \(\bA\).
Clearly, \(\| \bA \|_{0} = |\supp(\bA)|\).
We note that while \(\| \bA \|_{0}\) is not a norm, its behavior is similar to the \(\ell_0\)-“norm” for vectors \(\bv \in \RR^n\) defined as \(\| \bv \|_0 \triangleq | \supp(\bv) |\).
We use \(f(x)\) and \(F(x)\) to denote the PDF and CDF of a continuous random variable.
We use \(p(x)\) to denote the PMF of a discrete random variable.
We use \(\PP(E)\) to denote the probability of an event.
23.1.1. Problem Formulation#
The data set can be modeled as a set of data points lying in a union of low dimensional linear or affine subspaces in a Euclidean space \(\RR^M\) where \(M\) denotes the dimension of ambient space.
Let the data set be \(\{ \by_j \in \RR^M \}_{j=1}^S\) drawn from the union of subspaces under consideration.
\(S\) is the total number of data points being analyzed simultaneously.
We put the data points together in a data matrix as
\[ \bY \triangleq \begin{bmatrix} \by_1 & \dots & \by_S \end{bmatrix}. \]The data matrix \(Y\) is known to us.
Note that in statistic books, data samples are placed in each row of the data matrix. We are putting data samples in each column of the data matrix.
We will slightly abuse the notation and let \(\bY\) denote the set of data points \(\{ \by_j \in \RR^M \}_{j=1}^S\) also.
We will use the terms data points and vectors interchangeably.
Let the vectors be drawn from a set of \(K\) (linear or affine) subspaces.
The number of subspaces may not be known in advance.
The subspaces are indexed by a variable \(k\) with \(1 \leq k \leq K\).
The \(k\)-th subspace is denoted by \(\UUU_k\).
Let the (linear or affine) dimension of \(k\)-th subspace be \(\dim(\UUU_k) = D_k\) with \(D_k \leq D\).
Here \(D\) is an upper bound on the dimension of individual subspaces.
We may or may not know \(D\).
We assume that none of the subspaces is contained in another.
A pair of subspaces may not intersect (e.g. parallel lines or planes), may have a trivial intersection (lines passing through origin), or a non-trivial intersection (two planes intersecting at a line).
The collection of subspaces may also be independent or disjoint (see Linear Algebra).
The vectors in \(\bY\) can be grouped (or segmented or clustered) as submatrices \(\bY_1, \bY_2, \dots, \bY_K\) such that all vectors in \(\bY_k\) lie in subspace \(\UUU_k\).
Thus, we can write
\[ \bY^* = \bY \Gamma = \begin{bmatrix} \by_1 & \dots & \by_S \end{bmatrix} \Gamma = \begin{bmatrix} \bY_1 & \dots & \bY_K \end{bmatrix} \]where \(\Gamma\) is an \(S \times S\) unknown permutation matrix placing each vector to the right subspace.
This segmentation is straight-forward if the (affine) subspaces do not intersect or the subspaces intersect trivially at one point (e.g. any pair of linear subspaces passes through origin).
Let there be \(S_k\) vectors in \(\bY_k\) with \(S = S_1 + \dots + S_K\).
We may not have any prior information about the number of points in individual subspaces.
We do typically require that there are enough vectors drawn from each subspace so that they can span the corresponding subspace.
This requirement may vary for individual subspace clustering algorithms.
For example, for linear subspaces, sparse representation based algorithms require that whenever a vector is removed from \(\bY_k\), the remaining set of vectors spans \(\UUU_k\).
This guarantees that every vector in \(\bY_k\) can be represented in terms of other vectors in \(\bY_k\).
The minimum required \(S_k\) for which this is possible is \(S_k = D_k + 1\) when the data points from each subspace are in general position (i.e. \(\spark(\bY_k) = D_k + 1\)).
Let \(\bQ_k\) be an orthonormal basis for subspace \(\UUU_k\).
Then, the subspaces can be described as
\[ \UUU_k = \{ \by \in \RR^M \ST \by = \mu_k + \bQ_k \ba \}, \quad 1 \leq k \leq K \]For linear subspaces, \(\mu_k = \bzero\).
We will abuse \(\bY_k\) to also denote the set of vectors from the \(k\)-th subspace.
The basic objective of subspace clustering algorithms is to obtain a clustering or segmentation of vectors in \(\bY\) into \(\bY_1, \dots, \bY_K\).
This involves finding out the number of subspaces/clusters \(K\), and placing each vector \(\by_s\) in its cluster correctly.
Alternatively, if we can identify \(\Gamma\) and the numbers \(S_1, \dots, S_K\) correctly, we have solved the clustering problem.
Since the clusters fall into different subspaces, as part of subspace clustering, we may also identify the dimensions \(\{D_k\}_{k=1}^K\) of individual subspaces, the bases \(\{ \bQ_k \}_{k=1}^K\) and the offset vectors \(\{ \mu_k \}_{k=1}^K\) in case of affine subspaces.
These quantities emerge due to modeling the clustering problem as a subspace clustering problem.
However, they are not essential outputs of the subspace clustering algorithms.
Some subspace clustering algorithms may not calculate them, yet they are useful in the analysis of the algorithm.
See Data Clustering for a quick review of data clustering terminology.
23.1.2. Noisy Case#
We also consider clustering of data points which are contaminated with noise.
The data points do not perfectly lie in a subspace but can be approximated as a sum of a component which lies perfectly in a subspace and a noise component.
Let
\[ \by_s = \bar{\by}_s + \be_s , \Forall 1 \leq s \leq S \]be the \(s\)-th vector that is obtained by corrupting an error free vector \(\bar{\by}_s\) (which perfectly lies in a low dimensional subspace) with a noise vector \(\be_s \in \RR^M\).
The clustering problem remains the same. Our goal would be to characterize the behavior of the clustering algorithm in the presence of noise at different levels.
23.2. Linear Algebra#
This section reviews some useful concepts from linear algebra relevant for the chapter.
A collection of linear subspaces \(\{ \UUU^i\}_{i=1}^n\) is called independent if \(\dim(\oplus_{i=1}^n \UUU^i)\) equals \(\sum_{i=1}^n \dim (\UUU^i)\).
A collection of linear subspaces is called disjoint if they are pairwise independent [33]. In other words, every pair of subspaces intersect only at the origin.
23.2.1. Affine Subspaces#
For a detailed introduction to affine concepts, see [54].
For a vector \(\bv \in \RR^n\), the function \(f\) defined by \(f (\bx) = \bx + \bv, \bx \in \RR^n\) is a translation of \(\RR^n\) by \(\bv\).
The image of any set \(\SSS\) under \(f\) is the \(\bv\)-translate of \(\SSS\).
A translation of space is a one to one isometry of \(\RR^n\) onto \(\RR^n\).
A translate of a \(d\)-dimensional linear subspace of \(\RR^n\) is a \(d\)-dimensional flat or simply \(d\)-flat in \(\RR^n\).
Flats of dimension 1, 2, and \(n-1\) are also called lines, planes, and hyperplanes, respectively.
Flats are also known as affine subspaces.
Every \(d\)-flat in \(\RR^n\) is congruent to the Euclidean space \(\RR^d\).
Flats are closed sets.
Affine combinations
An affine combination of the vectors \(\bv_1, \dots, \bv_m\) is a linear combination in which the sum of coefficients is 1.
Thus, \(\bb\) is an affine combination of \(\bv_1, \dots, \bv_m\) if \(\bb = k_1 \bv_1 + \dots k_m \bv_m\) and \(k_1 + \dots + k_m = 1\).
The set of affine combinations of a set of vectors \(\{ \bv_1, \dots, \bv_m \}\) is their affine span.
A finite set of vectors \(\{\bv_1, \dots, \bv_m\}\) is called affine independent if the only zero-sum linear combination representing the null vector is the null combination. i.e. \(k_1 \bv_1 + \dots + k_m \bv_m = \bzero\) and \(k_1 + \dots + k_m = 0\) implies \(k_1 = \dots = k_m = 0\).
Otherwise, the set is affinely dependent.
A finite set of two or more vectors is affine independent if and only if none of them is an affine combination of the others.
Vectors vs. Points
We often use capital letters to denote points and bold small letters to denote vectors.
The origin is referred to by the letter \(O\).
An n-tuple \((x_1, \dots, x_n)\) is used to refer to a point \(X\) in \(\RR^n\) as well as to a vector from origin \(O\) to \(X\) in \(\RR^n\).
In basic linear algebra, the terms vector and point are used interchangeably.
While discussing geometrical concepts (affine or convex sets etc.), it is useful to distinguish between vectors and points.
When the terms “dependent” and “independent” are used without qualification to points, they refer to affine dependence/independence.
When used for vectors, they mean linear dependence/independence.
\(k\)-flats
The span of \(k+1\) independent points is a \(k\)-flat and is the unique \(k\)-flat that contains all \(k+1\) points.
Every \(k\)-flat contains \(k+1\) (affine) independent points.
Each set of \(k+1\) independent points in the \(k\)-flat forms an affine basis for the flat.
Each point of a \(k\)-flat is represented by one and only one affine combination of a given affine basis for the flat.
The coefficients of the affine combination of a point are the affine coordinates of the point in the given affine basis of the \(k\)-flat.
A \(d\)-flat is contained in a linear subspace of dimension \(d+1\).
This can be easily obtained by choosing an affine basis for the flat and constructing its linear span.
Affine functions
A function \(f\) defined on a vector space \(\VV\) is an affine function or affine transformation or affine mapping if it maps every affine combination of vectors \(\bu, \bv\) in \(\VV\) onto the same affine combination of their images.
If \(f\) is real valued, then \(f\) is an affine functional.
A property which is invariant under an affine mapping is called affine invariant.
The image of a flat under an affine function is a flat.
Every affine function differs from a linear function by a translation.
Affine functionals
A functional is an affine functional if and only if there exists a unique vector \(\ba \in \RR^n\) and a unique real number \(k\) such that \(f(\bx) = \langle \ba, \bx \rangle + k\).
Affine functionals are continuous.
If \(\ba \neq \bzero\), then the linear functional \(f(\bx) = \langle \ba, \bx \rangle\) and the affine functional \(g(\bx) = \langle \ba, \bx \rangle + k\) map bounded sets onto bounded sets, neighborhoods onto neighborhoods, balls onto balls and open sets onto open sets.
23.2.2. Hyperplanes and Halfspaces#
Corresponding to a hyperplane \(\HHH\) in \(\RR^n\) (an \(n-1\)-flat), there exists a non-null vector \(\ba\) and a real number \(k\) such that \(\HHH\) is the graph of \(\langle \ba , \bx \rangle = k\).
The vector \(\ba\) is orthogonal to \(PQ\) for all \(P, Q \in \HHH\).
All non-null vectors \(\ba\) to have this property are normal to the hyperplane.
The directions of \(\ba\) and \(-\ba\) are called opposite normal directions of \(\HHH\).
Conversely, the graph of \(\langle \ba , \bx \rangle = k\), \(\ba \neq \bzero\), is a hyperplane for which \(\ba\) is a normal vector. If \(\langle a, x \rangle = k\) and \(\langle \bb, \bx \rangle = h\), \(\ba \neq \bzero\), \(\bb \neq \bzero\) are both representations of a hyperplane \(\HHH\), then there exists a real non-zero number \(\lambda\) such that \(\bb = \lambda \ba\) and \(h = \lambda k\).
We can find a unit norm normal vector for \(\HHH\).
Each point \(P\) in space has a unique foot (nearest point) \(P_0\) in a Hyperplane \(\HHH\).
Distance of the point \(P\) with vector \(\bp\) from a hyperplane \(\HHH : \langle \ba , \bx \rangle = k\) is given by
\[ d(P, \HHH) = \frac{|\langle \ba, \bp \rangle - k|}{\| \ba \|_2}. \]The coordinate \(\bp_0\) of the foot \(P_0\) is given by
\[ \bp_0 = \bp - \frac{\langle \ba, \bp \rangle - k}{\| \ba \|_2^2} \ba. \]Hyperplanes \(\HHH\) and \(\mathcal{K}\) are parallel if they don’t intersect.
This occurs if and only if they have a common normal direction.
They are different constant sets of the same linear functional.
If \(\HHH_1 : \langle \ba , \bx \rangle = k_1\) and \(\HHH_2 : \langle \ba, \bx \rangle = k_2\) are parallel hyperplanes, then the distance between the two hyperplanes is given by
\[ d(\HHH_1 , \HHH_2) = \frac{| k_1 - k_2|}{\| \ba \|_2}. \]
Half-spaces
If \(\langle \ba, \bx \rangle = k\), \(\ba \neq \bzero\), is a hyperplane \(\HHH\), then the graphs of \(\langle \ba , \bx \rangle > k\) and \(\langle \ba , \bx \rangle < k\) are the opposite sides or opposite open half spaces of \(\HHH\).
The graphs of \(\langle \ba , \bx \rangle \geq k\) and \(\langle \ba , \bx \rangle \leq k\) are the opposite closed half spaces of \(\HHH\).
\(\HHH\) is the face of the four half-spaces.
Corresponding to a hyperplane \(\HHH\), there exists a unique pair of sets \(\SSS_1\) and \(\SSS_2\) that are the opposite sides of \(\HHH\).
Open half spaces are open sets and closed half spaces are closed sets.
If \(A\) and \(B\) belong to the opposite sides of a hyperplane \(\HHH\), then there exists a unique point of \(\HHH\) that is between \(A\) and \(B\).
23.2.3. General Position#
A general position for a set of points or other geometric objects is a notion of genericity.
It means the general case situation as opposed to more special and coincidental cases.
For example, generically, two lines in a plane intersect in a single point.
The special cases are when the two lines are either parallel or coincident.
Three points in a plane in general are not collinear.
If they are, then it is a degenerate case.
A set of \(n+1\) or more points in \(\RR^n\) is in said to be in general position if every subset of \(n\) points is linearly independent.
In general, a set of \(k+1\) or more points in a \(k\)-flat is said to be in general linear position if no hyperplane contains more than \(k\) points.
23.3. Matrix Factorizations#
23.3.1. Singular Value Decomposition#
A non-negative real value \(\sigma\) is a singular value for a matrix \(\bA \in \RR^{m \times n}\) if and only if there exist unit length vectors \(\bu \in \RR^m\) and \(\bv \in \RR^n\) such that \(\bA \bv = \sigma \bu\) and \(\bA^T \bu = \sigma \bv\).
The vectors \(\bu\) and \(\bv\) are called left singular and right singular vectors for \(\sigma\) respectively.
For every \(\bA \in \RR^{m \times n}\) with \(k = \min(m, n)\), there exist two orthogonal matrices \(\bU \in \RR^{m \times m}\) and \(\bV \in \RR^{n \times n}\) and a sequence of real numbers \(\sigma_1 \geq \dots \geq \sigma_k \geq 0\) such that \(\bU^T \bA \bV = \Sigma\) where \(\Sigma = \text{diag}(\sigma_1, \dots, \sigma_k, 0, \dots, 0) \in \RR^{m \times n}\) (Extra columns or rows are filled with zeros).
The decomposition of \(\bA\) given by \(\bA = \bU \Sigma \bV^T\) is called the singular value decomposition of \(\bA\).
The first \(k\) columns of \(\bU\) and \(\bV\) are the left and right singular vectors of \(\bA\) corresponding to the singular values \(\sigma_1, \dots, \sigma_k\).
The rank of \(\bA\) is equal to the number of non-zero singular values which equals the rank of \(\Sigma\).
The eigen values of positive semi-definite matrices \(\bA^T \bA\) and \(\bA \bA^T\) are given by \(\sigma_1^2, \dots, \sigma_k^2\) (remaining eigen values being \(0\)).
Specifically, \(\bA^T \bA = \bV \Sigma^T \Sigma \bV^T\) and \(\bA \bA^T = \bU \Sigma \Sigma^T \bU^T\).
We can rewrite \(\bA = \sum_{i=1}^k \sigma_i \bu_i \bv_i^T\).
\(\sigma_1 \bu_1 \bv_1^T\) is rank-1 approximation of \(\bA\) in Frobenius norm sense.
The spectral radius and \(2\)-norm of \(\bA\) is given by its largest singular value \(\sigma_1\).
The Moore-Penrose pseudo-inverse of \(\Sigma\) is easily obtained by taking the transpose of \(\Sigma\) and inverting the non-zero singular values.
Further, \(\bA^{\dag} = \bV \Sigma^{\dag} \bU^T\).
The non-zero singular values of \(\bA^{\dag}\) are just reciprocals of the non-zero singular values of \(\bA\).
Geometrically, singular values of \(\bA\) are the precisely the lengths of the semi-axes of the hyper-ellipsoid \(E\) defined by
\[ E = \{ \bA \bx \ST \| \bx \|_2 = 1 \} \](i.e. image of the unit sphere under \(\bA\)).
Thus, if \(\bA\) is a data matrix, then the SVD of \(\bA\) is strongly connected with the principal component analysis of \(\bA\).
23.4. Principal Angles#
If \(\UUU\) and \(\VVV\) are two linear subspaces of \(\RR^M\), then the smallest principal angle between them denoted by \(\theta\) is defined as [12]
\[ \cos \theta = \underset{\bu \in \UUU, \bv \in \VVV}{\max} \frac{\bu^T \bv}{\| \bu \|_2 \| \bv \|_2}. \]In other words, we try to find unit norm vectors in the two spaces which are maximally aligned with each other.
The angle between them is the smallest principal angle.
Note that \(\theta \in [0, \pi /2 ]\) (\(\cos \theta\) as defined above is always positive).
If we have \(\bU\) and \(\bV\) as matrices whose column spans are the subspaces \(\UUU\) and \(\VVV\) respectively, then in order to find the principal angles, we construct orthogonal bases \(\bQ_U\) and \(\bQ_V\).
We then compute the inner product matrix \(\bG = \bQ_U^T \bQ_V\).
The SVD of \(\bG\) gives the principal angles.
In particular, the smallest principal angle is given by \(\cos \theta = \sigma_1\), the largest singular value.
- 1
PCA can also be viewed as a statistical model. When the data points are independent samples drawn from a Gaussian distribution, the geometric formulation of PCA coincides with its statistical formulation.
- 2
We would use the terms arrangement and union interchangeably. For more discussion see Algebraic Geometry.